
delpho
DB에 대하여 - 2 본문
_1. 정규화에 대해서 설명해주세요.
# 정규화란?
- 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스
- 정규화의 기본 목표는 테이블 간에 중복된 데이타를 허용하지 않는다는 것
- 중복된 데이터를 허용하지 않음으로써 무결성(Integrity)를 유지 가능
- DB의 저장 용량 줄일 수 있음
- 이러한 테이블을 분해하는 정규화 단계가 정의되어 있는데, 여기서 테이블을 어떻게 분해되는지에 따라 정규화 단계가 달라지는데, 각각의 정규화 단계에 대해 자세히 알아보도록 하자.
# 정규화 단계
- 테이블을 어떻게 분해되는지에 따라 정규화 단계가 달라짐
1. 제1 정규화
- 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것
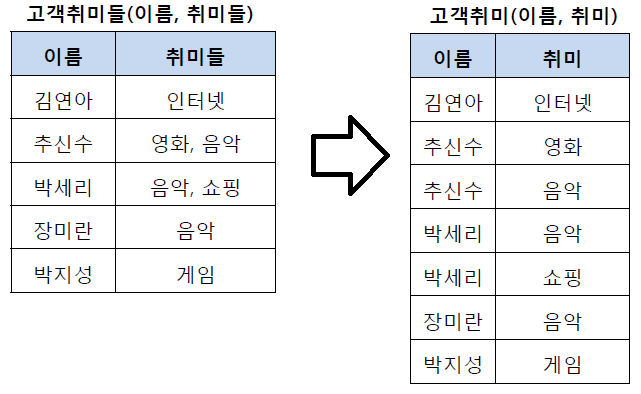
- 추신수와 박세리는 여러 개의 취미를 가지고 있기 때문에 제1 정규형을 만족하지 못하고 있음
2. 제2 정규화
- 제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것
- 완전 함수 종속 👉 기본키(2개 이상일때)중에 특정 컬럼에만 종속된 컬럼(부분적 종속)이 없어야 한다는 것

- 위 테이블의 경우 기본키는 (Student, Subject) 두 개로 볼 수 있습니다.이 두 개가 합쳐져야 한 로우를 구분할 수가 있습니다.
- 근데 Age의 경우 이 기본키중에 Student에만 종속되어 있습니다.
- 즉, Student 컬럼의 값을 알면 Age의 값을 알 수 있습니다.
- 따라서 Age가 두 번 들어가는 것은 불필요한 것으로 볼 수 있습니다.
- 이를 해결하기 위해 아래처럼 테이블을 쪼갬!


3. 제3 정규화
- 기본키를 제외한 속성들 간의 이행적 함수 종속이 없는 것
- 풀어서 말하자면, 기본키 이외의 다른 컬럼이 그외 다른 컬럼을 결정할 수 없는 것
- 3차 정규화는 2차정규화와 마찬가지로 테이블을 분리함으로써 해결할 수 있음!
- 아래와 같은 데이터 구성을 생각해봅시다.
- Student_id가 기본키이고, 기본키가 하나이므로 2차 정규형은 만족하는 것으로 볼 수 있습니다.
- 하지만 이 데이터의 Zip컬럼을 알면 Street, City, State를 결정할 수 있습니다.
- 또한 여러명의 학생들이 같은 Zip코드를 갖는 경우에 Zip코드만 알면 Street, City, State가 결정되기 때문이 이 컬럼들에는 중복된 데이터가 생길 가능성이 있습니다.

👇👇👇👇👇👇👇👇👇👇

4. BCNF 정규화
- 3차 정규형을 조금 더 강화한 버전
- 3차 정규형으로 해결할 수 없는 이상현상을 해결가능
- 3차정규형을 만족하면서 모든 결정자가 후보키 집합에 속한 정규형입니다.
- 아래와 같은 경우를 생각해보면, 후보키는 수퍼키중에서 최소성을 만족하는 건데, 이 경우 (학생, 과목) 입니다.
- (학생, 과목)은 그 로우를 유일하게 구분할 수 있습니다.
- 근데 이 테이블의 경우 교수가 결정자 입니다. (교수가 한 과목만 강의할 수 있다고 가정)
- 즉, 교수가 정해지면 과목이 결정됩니다. 근데 교수는 후보키가 아닙니다.
- 따라서 이 경우에 BCNF를 만족하지 못한다고 합니다.
- 3차 정규형을 만족하면서 BCNF는 만족하지 않는 경우는 언제일까요? 바로 일반 컬럼이 후보키를 결정하는 경우입니다.
- 아래와 같이 테이블이 구성된 경우에 데이터가 중복되고, 갱신 이상이 발생합니다.
- 예를 들어 Mr.Sim이 강의하는 과목명이 바뀌었다면 두 개의 로우를 갱신해야합니다.
- 이를 해결하기 위해서는 마찬가지로 테이블을 분리합니다.

👇👇👇👇👇👇👇👇👇👇

_2. JOIN에 대해서 설명해주세요.
# join
두개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
# join의 종류
inner join
outer join (left / right / full)
cross join
self join
- inner join
- 양쪽 테이블 데이터 집합에서 공통적으로 존재하는 데이터만 결과 데이터 집합으로 추출


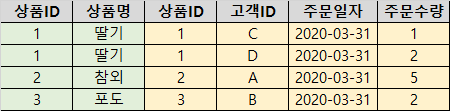
SELECT p.상품ID, p.상품명, o.상품ID, o.고객ID, o.주문일자, o.주문수량
FROM 상품 p
JOIN 고객주문상품 o
ON p.상품ID = o.상품ID;
- left outer join
- 양쪽 테이블 데이터 집합에서 공통적으로 존재하는 데이터 + Left outer join 키워드 왼쪽에 명시된 테이블에만 존재하는 데이터를 결과 데이터 집합으로 추출
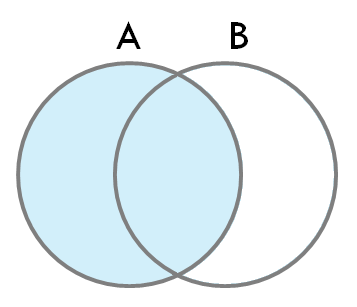
SELECT p.상품ID, p.상품명, o.상품ID, o.고객ID, o.주문일자, o.주문수량
FROM 상품 p
LEFT OUTER JOIN 고객주문상품 o
ON p.상품ID = o.상품ID;

- right outer join
- 양쪽 테이블 데이터 집합에서 공통적으로 존재하는 데이터 + right outer join 키워드 오른쪽에 명시된 테이블에만 존재하는 데이터를 결과 데이터 집합으로 추출

SELECT p.상품ID, p.상품명, o.상품ID, o.고객ID, o.주문일자, o.주문수량
FROM 상품 p
RIGHT OUTER JOIN 고객주문상품 o
ON p.상품ID = o.상품ID;

- full outer join
- 양쪽 테이블 데이터 집합에서 공통적으로 존재하는 데이터 + 각각 테이블에만 존재하는 데이터도 모두 결과 데이터 집합으로 추출

SELECT p.상품ID, p.상품명, o.상품ID, o.고객ID, o.주문일자, o.주문수량
FROM 상품 p
FULL OUTER JOIN 고객주문상품 o
ON p.상품ID = o.상품ID;

- cross join
- 양쪽 테이블 데이터 집합에서 연결 가능한 행을 모두 결합하여 결과 데이터 집합으로 추출
SELECT * FROM employee CROSS JOIN department;

- self join
- 자기 자신 테이블 데이터 집합에서 공통적으로 존재하는 데이터를 결과 데이터 집합으로 추출
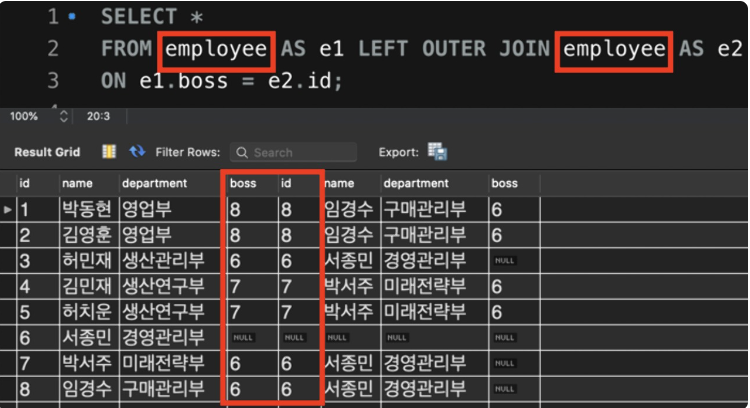
- employee 테이블의 boss 컬럼과 id 컬럼을 기준으로 LEFT OUTER JOIN인 SELF JOIN을 했더니 각 직원 옆에 직속 상사 정보도 함께 뜸!
_3. RDBMS vs NOSQL에 대해서 설명해주세요.
# RDBMS
- 데이터를 2차원의 테이블 형태로 표현하고 테이블 간의 관계를 가질 수 있는 관계형 데이터베이스를 관리할 수 있는 소프트웨어
- 명확한 데이터 구조를 보장
- SQL 언어을 사용하여 데이터를 조작
- ORACLE, MySQL, Maria DB 등
# NoSQL
- 데이터와 트래픽 양이 급증하면서 관계형 데이터베이스를 사용하는 것이 하드웨어적으로 큰 비용이 듬 👉 데이터의 일관성을 약간 포기한 대신 여러 대의 컴퓨터에 데이터를 분산하여 저장하는 것(Scale-out : 수평적 확장)을 목표로 등장
- RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술.
- RDBMS와는 달리 테이블 간 관계를 정의하지 않는다.
- 스키마가 없기 때문에 유연하며 자유로운 데이터 구조를 가질 수 있음
- 데이터 일관성이 보장되지않음
- Redis or MongoDB 등
# NoSQL 종류
- Key-value
-
Document
-
Column-family
-
Graph
출처
https://3months.tistory.com/193
데이터베이스 정규화 1NF, 2NF, 3NF, BCNF
데이터베이스 정규화 1NF, 2NF, 3NF, BCNF 데이터베이스 정규화란 데이터베이스의 설계를 재구성하는 테크닉입니다. 정규화를 통해 불필요한 데이터(redundancy)를 없앨 수 있고, 삽입/갱신/삭제 시 발
3months.tistory.com
https://mangkyu.tistory.com/110
[Database] 정규화(Normalization) 쉽게 이해하기
지난 포스팅에서 데이터베이스 정규화와 관련된 내용을 정리했었다. 하지만 해당 내용이 쉽게 이해되지 않는 것 같아서 정규화 관련 글을 풀어서 다시 한번 정리해보고자 한다. 1. 정규화(Normaliz
mangkyu.tistory.com
https://sparkdia.tistory.com/17
테이블 조인 종류(Table Join Type)
데이터베이스에서 데이터는 다수의 테이블에 나뉘어 저장되어 있습니다. 데이터의 중복을 제거하고 무결성을 보장하기 위해서 데이터 성격에 따라 분류하여 테이블에 저장을 하는 겁니다. 이
sparkdia.tistory.com
https://data-make.tistory.com/24
[SQL] 조인의 모든 것 - Join, Cartesian Product, EQUI, Non-Equi, Outer, Sefl
여러 테이블의 데이터를 조회하기 - JOIN SQL 에서 Join 은 언제 사용할까요? group by 절을 설명할 때에도 한 번 언급하긴 했었는데, 여러 테이블로 나뉘어진 데이터를 조회하기 위해 사용한다고 생
data-make.tistory.com
https://www.theteams.kr/teams/8573/post/73290
SQL의 핵심, 다양한 종류의 조인 by 코드잇
이전 글인 \'SQL의 핵심, 여러 테이블을 다루는 조인(LEFT OUTER JOIN, RIGHT OUTER JOIN)\'에서는 여러가지 종류의 조인들 중에서도 특히 실무에서의 활용도가 높은 LEFT OUTER JOIN과 RIGHT OUTER JOIN에 대해
www.theteams.kr
https://khj93.tistory.com/entry/Database-RDBMS%EC%99%80-NOSQL-%EC%B0%A8%EC%9D%B4%EC%A0%90
[Database] RDBMS와 NoSQL의 차이점
이번 포스팅에서는 RDBMS와 NoSQL의 차이점을 알아보려고 합니다. 그전에 RDBMS는 무엇이고 왜 사용하며 NoSQL은 무엇이고 왜 사용을 할까요? 그리고 그 두 DB의 차이점은 무엇이며 서로에 대한 장단점
khj93.tistory.com
NoSQL - 나무위키
“Not Only SQL” : 데이터를 저장하는 데에는 SQL 외에 다른 방법들도 있다. NoSQL이라고 하는 말은 No 'English'라고 하는 말과 마찬가지다. 세상에는 영어 말고도 수많은 언어가 존재한다. MongoDB에서 사
namu.wiki